Overview of Fed2Tier
Introduction
Federated Learning is a machine learning technique for training models on distributed data without sharing it. In traditional machine learning, large datasets must first be collected and then sent to one location where they can be combined before the model is trained on them. However, this process can cause privacy concerns as sensitive personal data may become publicly available. Federated learning attempts to address these concerns by keeping individual user’s data local while still allowing for powerful powerful statistical analysis that can be used to create accurate models at scale.
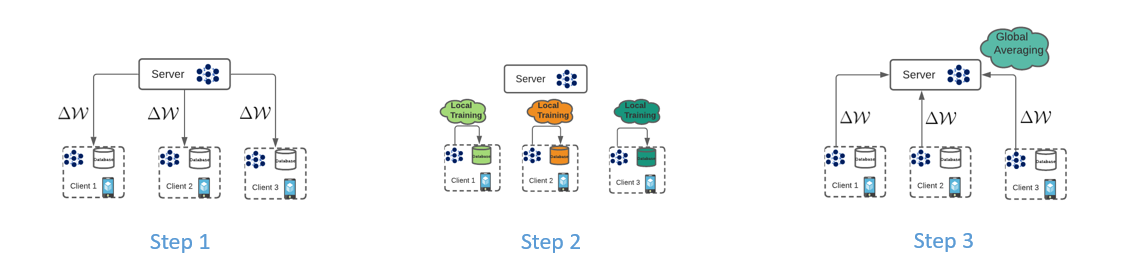
FedAvg is one of the foundational blocks of federated learning. A single communication round of FedAvg includes:
Waiting for a number of clients to connect to a server (Step 0)
Sending the clients a global model (Step 1)
Train the model with locally available data (Step 2)
Send the trained models back to the server (Step 3)
The server then averages the weights of the models and calculates a new aggregated model. This process constitutes a single communication round and several such communication rounds occur to train a model.
Overview
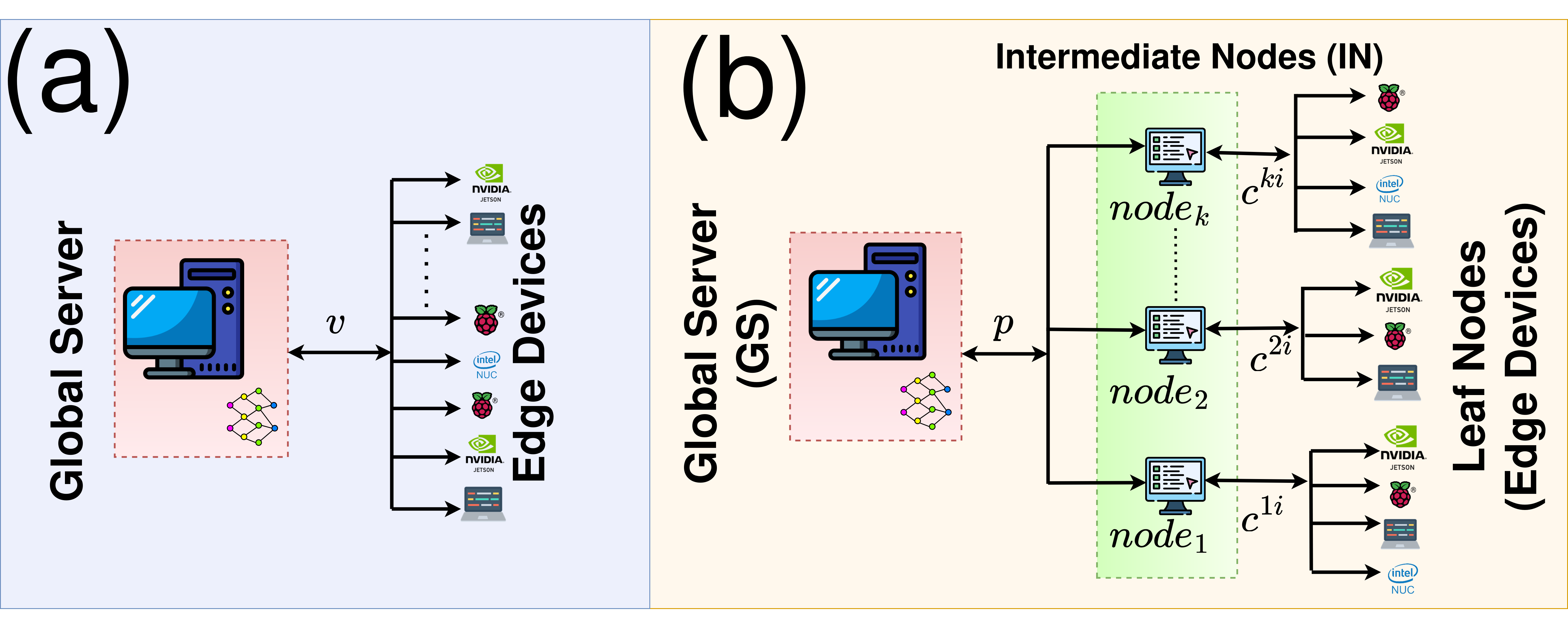
Fed2Tier introduces a unique two-level federated learning system focused on achieving both efficient and eco-friendly computation. This method in distributed machine learning prioritizes privacy, scalability, and a greener footprint. By categorizing clients based on their individual characteristics and subsequently grouping them, Fed2Tier effectively addresses variations in underlying data distributions. The introduction of intermediate nodes has concurrently reduced both communication rounds and carbon emissions during training, ensuring increased privacy and efficiency.
Key Features
Two-Level Architecture: Fed2Tier’s unique two-tier system integrates both client devices and intermediate nodes, optimizing the training process and data aggregation.
Eco-friendly Computation: Prioritizes reduced carbon emissions during training, making it a green choice for large-scale distributed machine learning.
Dynamic Categorization: Clients are categorized based on their individual characteristics, ensuring efficient data handling and model training.
Architecture
Benefits
Enhanced Model Generalizability: By involving a larger number of edge devices in training, models achieve better adaptability and performance.
Reduced Carbon Emissions: Eco-friendly design leads to minimized carbon footprint during the training process.
Increased Data Privacy: Data remains on edge devices, ensuring users’ data privacy and security.
Tested on
Fed2Tier has been extensively tested on and works with the following devices:
Intel CPUs
Nvidia GPUs
Nvidia Jetson
Raspberry Pi
Intel NUC